지난포스팅 참조
지난번에 공공데이터를 활용하여 2022년 7월 31일까지 지자체에 신고된 '일반음식점' 현황을 가져와 봤습니다.
전국 일반음식점 신고현황 데이터 살펴보기
시작하기 전에 행정이 전산화되면서 공공기관에 신고, 등록, 인증, 허가되는 거의 모든 정보가 공공데이터로 제공되고 있습니다. 이렇게 제공되는 수많은 데이터를 잘 활용하면 유용한 정보가
blog.bluedawn.kr
일반음식점의 전체 데이터의 행이 2,012,833개라는 것을 확인했었는데요. 엑셀로 열 수 없을만큼 데이터가 방대하므로 조금 정리해 보겠습니다. 이 데이터에는 폐업으로 현재 영업을 하고 있지 않은 신고내역까지 포함하고 있으므로 폐업한 업체를 확인하여 삭제해 보겠습니다.
kind = '상세영업상태명'
count_labels = df[kind].value_counts().index.tolist()
count_values = df[kind].value_counts().values.tolist()
df_kind = pd.DataFrame({'검색열의 종류': count_labels, '총수': count_values})
df_kind> 실행결과
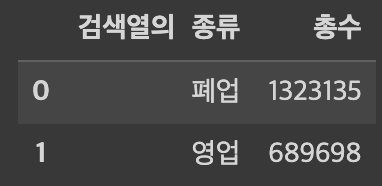
전체 목록에서 폐업한 업소가 1,323,135개, 현재 영업중인 업소가 689,698개 인것을 확인할 수 있습니다. 전체목록에서 폐업한 업체의 정보가 더 많네요. 그러면 데이터프레임 항목(열)중에서 '상세영업상태명'이 '영업'으로된 행만 추출해 보겠습니다.
df = df[df.상세영업상태명==str('영업')]
df.shape> 실행결과
(689698, 48)정상영업중인 업체 항목만 추려서 행이 정리되었습니다. 앞에서 '상세영업상태명' 열에 어떤 항목이 얼마나 있는지 알아봤던 코드를 이용하여 일반음식점 이름으로 어떤 이름을 많이 사용하고 있는지 알아보겠습니다.
kind = '사업장명'
count_labels = df[kind].value_counts().index.tolist()
count_values = df[kind].value_counts().values.tolist()
df_kind = pd.DataFrame({'검색열의 종류': count_labels, '총수': count_values})
df_kind.head(20)> 실행결과

상위 20개의 항목만 불러와 봤습니다. 우리들의 김밥천국이 탑을 찍었네요. 전반적으로 프랜차이즈 업소 이름이 많이 보입니다. 요즘에 투다리 많이 안보이던데 투다리가 3위군요. 하위 20위도 살펴보겠습니다.
df_kind.tail(20)> 실행결과
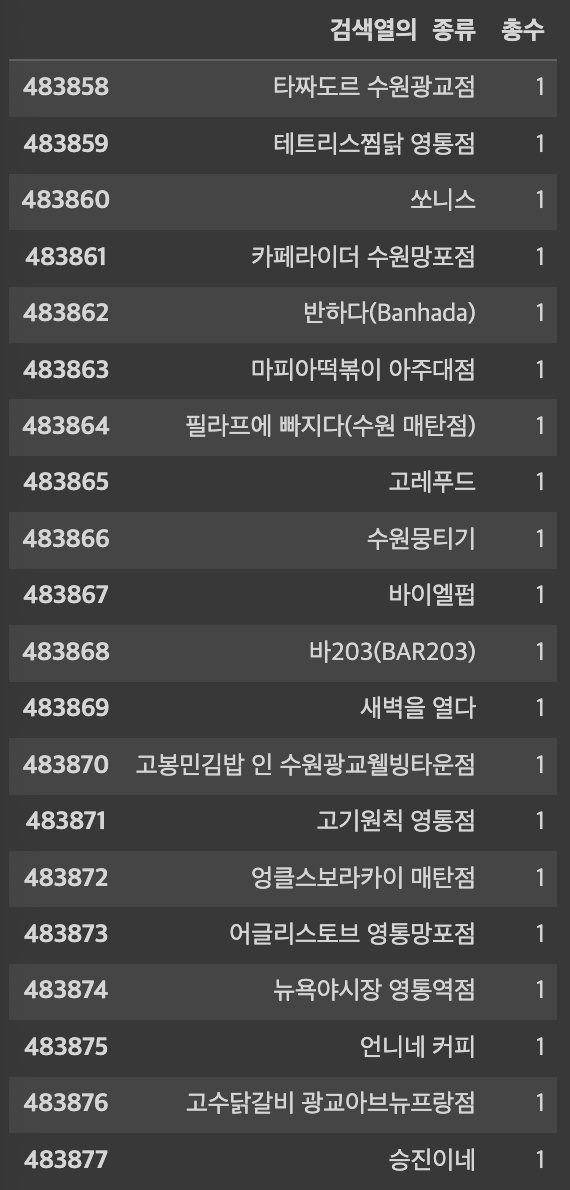
하위권 일반음식점 상효명을 보니 00점이 붙은 상호가 많네요. 고봉민김밥 같은 경우 프랜차이즈라 상당히 많이 신고가 되어 있을거 같은데 뒤에 00점이 붙어서 각각 카운트되니 순위에서 밀린거 같습니다. 맨 앞에있는 상호명만 뗴다가 순위를 살펴보겠습니다.
storeName = df['사업장명'].tolist()
storeName_list = []
for i in range(len(storeName)) :
name = f'{storeName[i]}'.split()
storeName_list.append(name[0])
df['수정_사업장명'] = storeName_list
df_new = pd.DataFrame({'사업장명':df['사업장명'], '수정_사업장명':df['수정_사업장명']})
df_new> 실행결과
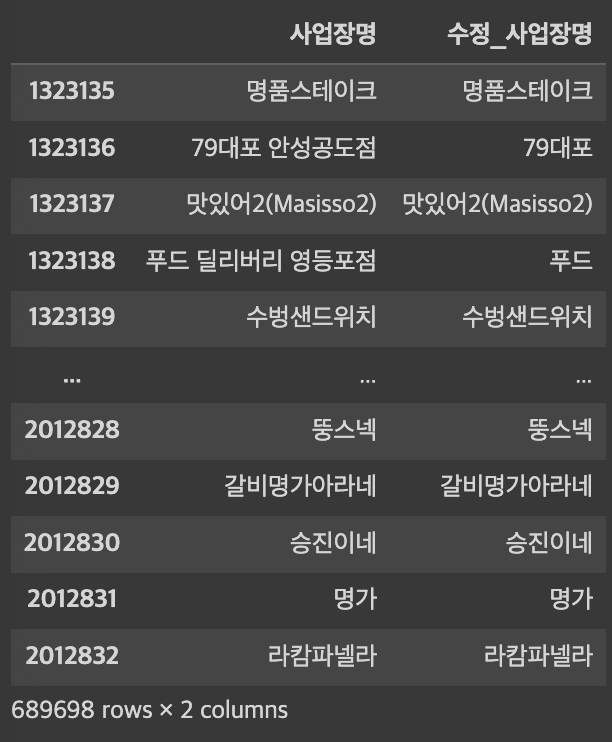
두번째 줄에 '79대포'의 경우 뒤에 '안성공도점'이라는 지점명이 빠지면서 '79대포'만 남은 것을 확인할 수 있습니다. 네번쨰 준에 '푸드 딜리버리 영등포점'의 경우 영등포점만 떨어져 나가야 하는데 '푸드'만 남았네요;;; 좀 더 꼼꼼한 가공이 필요하겠지만 이정도로 살펴보겠습니다.
kind = '수정_사업장명'
count_labels = df_new[kind].value_counts().index.tolist()
count_values = df_new[kind].value_counts().values.tolist()
df_kind = pd.DataFrame({'검색열의 종류': count_labels, '총수': count_values})
df_kind.head(30)> 실행결과

수정된 사업장명을 가지고 상위 30위까지 뽑아봤습니다. 앞글자만 따다보니 '카페', '더'와 같이 상호와 무관한 단어가 랭크에 올라갔네요. 그것을 제외하고 보면 역시 프랜차이즈가 압도적이네요. '역전할머니맥주'라는 상호는 생소한데 상위에 랭크되어 있어서 검색해 봤더니 이것도 프랜차이즈네요. 인기가 많은가 봅니다.
마지막으로 일반음식점 상호명을 가지고 '워드클라우드'를 만들어 보겠습니다. 워드클라우드는 단어 리스트를 가지고 반복되는 빈도에 따라 글자크리를 다르게 하여 시각화 하는 것입니다.
from wordcloud import WordCloud
dlist = df_kind['검색열의 종류'].tolist()
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
tempData = ' '.join(dlist)
wc = WordCloud(max_words = 1500, width = 1600, height = 800, font_path = fontpath).generate(tempData)
plt.imshow(wc, interpolation = 'bilinear')> 실행결과

읿반음식점 상호를 시각적으로 한눈에 파악해 보기 위해서 워드클라우드로 만들어 봤는데요, '카페, 식당, 주, cafe, coffee, 본점' 등 상호와 상관없는 단어가 많이 보이네요. 너무 부각되는 단어들을 치워 보겠습니다.

커피를 치우고 나니 치킨만 남네요. 언제나 우리에게 가까우 커피와 치킨~ 이번 포스팅은 여기까지 입니다.
'일반행정' 카테고리의 다른 글
| 돈 빌려주고 받기 - 법으로 보는 금전거래 (0) | 2022.08.21 |
|---|---|
| 일반음식점에는 어떤 업종이 있을까? (2) | 2022.08.21 |
| 전국 일반음식점 신고현황 데이터 살펴보기 (1) | 2022.08.18 |
| 사업자등록 하러 세무서 가세요? (0) | 2022.06.30 |
| 산림자원을 활용한 예비사회적기업에 공모하세요 (0) | 2022.06.24 |





댓글